I riassunti , gli appunti i testi contenuti nel nostro sito sono messi a disposizione gratuitamente con finalità illustrative didattiche, scientifiche, a carattere sociale, civile e culturale a tutti i possibili interessati secondo il concetto del fair use e con l' obiettivo del rispetto della direttiva europea 2001/29/CE e dell' art. 70 della legge 633/1941 sul diritto d'autore
Le informazioni di medicina e salute contenute nel sito sono di natura generale ed a scopo puramente divulgativo e per questo motivo non possono sostituire in alcun caso il consiglio di un medico (ovvero un soggetto abilitato legalmente alla professione).
2 – AGENTI INTELLIGENTI
Agente è qualunque entità in grado di percepire il proprio ambiente tramite sensori ed agire su di esso tramite attuatori.
L’agente interagisce con il suo ambiente per conto di un utente finale.
L’agente può essere robotico o semplicemente un software.
Scopo dell’AI è trovare il modo per costruire agenti efficienti.
Agente razionale è l’agente che agisce nel modo giusto, ossia con azioni che procurano il maggior successo.
Ciò che è razionale dipende da:
Agente razionale ideale è quello che per ogni sequenza di percezione possibile compie le azioni che massimizzano la sua misura di prestazione, sulla base delle prove fornite dalla sequenza di percezione e delle sue conoscenze predefinite.
Possiamo descrivere un agente elencando le azioni che compie in risposta ad ogni sequenza di percezione possibile. Questa lista è detta corrispondenza dalle sequenze di percezione alle azioni.
Corrispondenze ideali descrivono agenti ideali.
Progetto per un agente ideale è la specifica di quali azioni l’agente deve compiere in risposta ad una qualsiasi sequenza di percezione.
Non è necessario fornire un elenco esaustivo, basta un programma software.
Es: agente radice quadrata.
Caratteristiche di un agente software sono:
Sistemi Multi Agente sono una rete di risolutori di problemi che lavorano insieme per cercare una soluzione a problemi troppo complessi per un unico agente.
Esempi di agenti software (softbot) : assistenti per il web, la posta, l’agenda. Agenti collaborativi sono gli agenti per mediazioni commerciali, aste on line, logistica.
Autonomia
Se l’agente si basa solo sulle sue conoscenze predefinite, diciamo che manca di autonomia.
Un sistema è autonomo quando il suo comportamento viene determinato dalla sua esperienza personale.
Tuttavia una base di conoscenze predefinite iniziali aiuta l’apprendimento.
Compito dell’AI è progettare il programma di un agente: una funzione che implementa la corrispondenza dell’agente dalle percezioni alle azioni.
Il programma avrà un’architettura , ossia un meccanismo di calcolo: può basarsi su hardware e software.
L’architettura fornisce le percezioni dai sensori, esegue il programma, trasmette le scelte al programma degli attuatori:
agente = architettura + programma .
Si può descrivere un agente secondo il paradigma PAGE:
Tipo di agente |
Percezioni |
Azioni |
Obiettivi |
Ambiente |
Sistema di diagnosi medica |
Sintomi, referti, esame obiettivo |
Domande, test, terapie |
Paziente in salute |
Paziente, ospedale |
Sistema analisi immagini da satellite |
Pixel di intensità e colore variabile |
Stampare la categorizzazione corretta di una scena |
Correggere la categorizzazione |
Sistema satellitare |
Robot che raccoglie parti |
Pixel di intensità variabile |
Raccogliere parti e ordinarle |
Posizionare le parti nei contenitori corretti |
Nastro trasportatore con parti |
Controllore di raffineria |
Lettura di temperatura e pressione |
Aprire e chiudere valvole; regolare la temperatura |
Massimizzare purezza, qualità, sicurezza |
Raffineria |
Tutore interattivo di inglese |
Parole digitate |
Stampare esercizi, suggerimenti, correzioni |
Massimizzare i punteggi dello studente nei test |
Insieme di studenti |
Alcuni ambienti per agenti hardware (robot) sono molto limitati (v. fabbrica). Altri per agenti software sono molto estesi (v. per un simulatore di volo).
La distinzione fra ambiente reale ed artificiale è sfumata.
AGENTE BANALE
Un agente banale ha una memoria che viene aggiornata ad ogni nuova percezione, viene scelta l’azione migliore e questa viene aggiunta in memoria.
L’obiettivo non è parte del programma, viene controllato esternamente.
Un agente banale contiene una tabella che fa corrispondere un’azione ad ogni possibile sequenza di percezioni.
Questo agente fallirà, perché:
La tabella avrebbe bisogno di un numero estremamente alto di voci
La costruzione della tabella richiederebbe un tempo enorme
L’agente non ha alcuna autonomia: se l’ambiente cambia, l’agente è perduto.
Un meccanismo di apprendimento su tutta la tabella richiederebbe un tempo infinito.
Un agente che ragiona non consulta semplicemente una tabella.
UN ESEMPIO
Prendiamo l’agente conducente automatico di taxi:
Tipo di agente |
Percezioni |
Azioni |
Obiettivi |
Ambiente |
Conducente di taxi |
Telecamere, tachimetro, GPS, sonar, microfono |
Sterzare, accelerare, frenare, parlare al passeggero |
Viaggio sicuro, veloce, corretto |
Strade, |
Il conducente dovrà conoscere attraverso le percezioni:
I sensori necessari saranno:
accelerometro, sensori nel motore, GPS, sonar per le distanze dai veicoli, microfono per i clienti.
Le azioni saranno: attivazione di motore, di volante e freni, sintetizzatore vocale.
Misura di prestazione:
Ambiente:
tanto più si restringe tanto più è facile il progetto.
Realizziamo quattro tipi di agenti:
AGENTI CON RIFLESSI SEMPLICI
Impossibile realizzare una tabella (un’ora di telecamera a 25 immagini al secondo è pari a 2 60x60x50 M voci).
Riassumiamo molti elementi della tabella con regole condizione-azione :
if macchina_davanti_frena then inizia_a_frenare
Gli uomini usano molte di queste regole, apprese o innate.
Allora il programma dell’agente sarà:
Ma questo agente funziona solo se sulla base della percezione attuale può essere generata una decisione corretta.
AGENTE CHE TIENE CONTO DEL MONDO
Se non è possibile stabilire una regola da una sola percezione (es. diverse configurazioni delle luci) , l’agente con riflessi semplici fallirà.
Un agente migliore dovrà mantenere uno stato interno per scegliere un’azione (es. l’inquadratura precedente per stabilire se le luci si accendono simultaneamente).
Per aggiornare lo stato interno:
Viene quindi creata, accanto a quelle già viste, una nuova funzione AGGIORNA_STATO che utilizza queste informazioni per creare la descrizione del nuovo stato interno
AGENTE BASATO SU OBIETTIVI
Il taxi deve anche prendere decisioni su doove andare , ad es. quando arriva ad un incrocio: ha bisogno di informazioni sull’obiettivo.
Lìagente dovrà elaborare una sequenza di azioni per raggiungere l’obiettivo: i sottocampi dell’AI che si occupano i trovare queste sequenze di azioni sono la ricerca e la pianificazione.
Questo agente frenerà quando vede le luci di arresto non perché ha una regola che lo obbliga a farlo, ma perché questa è l’azione che alla lunga lo porterà all’obiettivo cui deve giungere.
L’agente basato su obiettivi è molto più flessibile: se cambia l’obiettivo (es. il luogo da raggiungere) funzionerà lo stesso, mentre l’agente con riflessi dovrà riscrivere tutte le regole su dove girare.
AGENTE BASATO SU UTILITA’
Gli obiettivi da soli non bastano a dare alte prestazioni: molti sono i percorsi che portano ad una meta, ma solo alcuni sono quelli rapidi ed affidabili.
Dobbiamo aggiungere una funzione che valuta il grado di soddisfazione dell’agente, la maggiore utilità .
Utilità è una funzione che fa corrispondere ad uno stato un numero reale, il grado di soddisfazione o di felicità.
Se ci sono diversi obiettivi, la funzione utilità valuta anche la probabilità di successo rispetto all’importanza degli obiettivi.
Un agente con la funzione di utilità può prendere decisioni razionali.
AMBIENTI
Ogni agente opera in un ambiente. Gli ambienti possono essere differenti.
Distinguiamo i seguenti tipi di ambiente:
Accessibile/inaccessibile : se i sensori danno all’agente accesso allo stato completo dell’agente, o meno.
Deterministico/non deterministico : se lo stato successivo è completamente determinato da quello precedente e dalle azioni dell’agente, o meno.
A volte un ambiente inaccessibile può sembrare non deterministico: parleremo di ambiente determinstico o meno dal punto di vista dell’agente.
Episodico/non episodico : ogni episodio è dato dalle percezioni e dalle conseguenti azioni dell’agente. Nel caso episodico, episodi successivi non dipendono da quali azioni accadono negli episodi precedenti: è più semplice.
Statico/dinamico : un ambiente è dinamico se può cambiare mentre l’agente sta deliberando. Gli ambienti statici sono più semplici.
Discreto/continuo : un ambiente è discreto se descritto da un numero limitato di percezioni e conseguenti azioni: scacchi discreto, taxi continuo.
Differenti ambienti richiedono agenti molto diversi.
PROGRAMMI DI AMBIENTI
La relazione fra agenti ed ambienti è regolata da un programma.
Dato un agente come input, il programma stabilisce di dare all’agente le giuste percezioni e ricevere in cambio un’azione.
Aggiorna poi l’ambiente in base alle azioni.
L’ambiente è definito dallo stato iniziale e dalla funzione di aggiornamento.
Un’altra procedura valuta le prestazioni di ogni agente restituendo un punteggio cumulativo (es. quantità di sporcizia raccolta dall’agente aspirapolvere) , per ogni singolo ambiente.
Ogni agente è progettato per agire in una classe di ambienti, e la valutazione delle prestazioni avverrà sulla media nella classe. Questa misura si produce facilmente utilizzando un simulatore.
PERCEZIONE
La percezione fornisce agli agenti le informazioni sul mondo, ed è permessa dai sensori.
Visione, udito e tatto sono le percezioni umane ma anche quelle simulate dai robot.
Se S è lo stimolo sensoriale e W il mondo, e la funzione f descrive il modo in cui si genera lo stimolo sensoriale e
S = f(W)
Per conoscere W si potrebbe calcolare W = f-1(S) , ma l’inversa di f non è nota, perchè dallo stimolo non si riesce a ricostruire il mondo. D’altra parte l’agente non ha bisogno di conoscere tutti i dettagli del mondo: basta ad es. che sappia dove sono gli ostacoli e che sappia riconoscere gli oggetti che deve usare, per le principali funzioni cui è deputato:
La visione funziona grazie all’acquisizione della luce riflessa dagli oggetti in una scena, creando un’immagine bidimensionale.
Pensiamo ad una scatola nera con un forellino. Sia P un punto della scena di coordinate (X,Y,Z). L’immagine che arriva alla parete opposta della scatola nera è invertita rispetto alla scena, con coordinate che seguono il processo di proiezione prospettica.
Sia che si pensi all’occhio umano, sia che si pensi alla telecamera , il piano immagine è suddiviso in pixel, ad es. 512 x 512 ( 0.25 x 106) nella telecamera, e 120 x 106 bastoncelli e 6 x 106 coni nell’occhio.
La luminosità di un pixel p nell’immagine è proporzionale ala quantità di luce diretta verso il sensore visivo dalla porzione di superficie S che proietta il pixel p. Ciò dipende dalla riflettanza di S e dalla posizione e distribuzione delle sorgenti luminose.
Nel mondo reale le superfici mostrano proprietà di diffusione e riflessione. La computer graphics si occupa di modellare e rendere questi effetti, tracciando dei raggi che simulano la direzione della luce. In visione automatica, invece, si risolve il problema inverso di determinare la forma della scena a partire dall’immagine visualizzata.
Un passo importante è quello di visualizzare i bordi degli oggetti, che sono poi linee rette o curve nel piano immagine in cui sono rilevabili significativi cambiamenti di luminosità.
Se I è l’intensità luminosa, un’idea potrebbe essere di individuare i punti in cui la derivata I’(x) è grande . Ma spesso i picchi della derivata sono dovuti a rumore.
Si migliorano le cose applicando lo smoothing o perequazione.
Una volta marcati tutti i pixel dei bordi, vanno uniti i bordi che appartengono alla stessa curva.
Si assume per questo che due pixel vicini corrispondano alla stessa curva, quindi allo stesso contorno.
Per eseguire manipolazione, determinazione di posizione, forma e orientamento degli oggetti, sono necessari i seguenti passi:
La segmentazione divide la scena in entità semanticamente rilevanti.
Il rilevamento dei bordi è l’operazione preliminare ma non è sufficiente: alcune frazioni dei bordi potrebbero essere poco contrastate, e molti bordi potrebbero essere solo rumore o segni o ombre.
La posizione di un punto P in una scena è data dalle coordinate (X,Y,Z) del punto, in cui l’origine è nel forellino della scatola nera e z è l’asse ottico. Noi disponiamo della proiezione prospettica del punto (x,y) dell’immagine, ma non sappiamo la distanza.
Quando la scatola nera viene spostata rispetto ad un oggetto, sia distanza che orientazione cambiano, ma viene preservata la forma (che non cambia mai se si sottopone l’oggetto a rototraslazioni).
La geometria differenziale si occupa di studiare come cambia invece la forma locale di una superficie: ad es. un cilindro che si muove parallelamente all’asse non avrà cambiamenti, mentre se si muove perpendicolarmente , la normale alla superficie ruota ad un tasso inversamente proporzionale al raggio del cilindro.
Forma geometrica, colore e tipo di superficie costituiscono gli indizi principali per identificare gli oggetti.
Per recuperare l’informazione tridimensionale perduta ci si serve di una serie di indizi visuali:
movimento, stereoscopia binoculare, texture (consistenza dei materiali superficiali), ombreggiatura, contorni.
Se la scatola nera si muove rispetto alla scena, il movimento apparente dell’immagine è detto flusso ottico. Si può rappresentare con vettori che indicano le velocità dei punti dell’oggetto. Gli oggetti lontani hanno movimento apparente più lento, quindi la velocità del movimento apparente dà indicazioni sulla distanza.
STEREOSCOPIA BINOCULARE
Vengono usate due immagini istantanee separate nello spazio invece che nel tempo, analogamente a quanto avviene con le immagini fornite dai due occhi.
Se si sovrappongono le due immagini, si avrà una disparità nella localizzazione dell’oggetto nelle due immagini. Esiste una relazione geometrica fra disparità e profondità.
Ad esempio nel caso in cui entrambe le telecamere sono orientate in avanti con i rispettivi assi ottici paralleli, la relazione fra le due è la traslazione lungo l’asse x di una quantità b. La disparità verticale sarà nulla, quella orizzontale sarà il rapporto fra b e la profondità.
In generale la disparità si valuta cercando punti corrispondenti fra l’immagine sinistra e la destra massimizzando qualche misura di similarità. I punti corrispondenti vanno cercati sulle cosiddette linee epipolari delle due immagini, ossia linee che corrispondono all’intersezione del piano epipolare con i piani di immagine sinistro e destro. Il piano epipolare va da un punto della scena ai due occhi. In questo modo un problema bidimensionale diventa unidimensionale.
GRADIENTI DI TEXTURE
Texture è una struttura che si ripete spazialmente su di una superficie: ad es. il posizionamento delle finestra di un palazzo, le macchie di leopardo, i fili d’erba nel prato, i ciottoli di una spiaggia, ecc.
A volte la regolarità è periodica, a volte solo statistica.
E’ possibile valutare la variazione della texture attraverso la variazione delle aree o la densità. Questi gradienti di texture sono funzioni della forma di una superficie e dell’orientamento rispetto al punto di vista. Dunque una volta valutati i gradienti di texture si possono ipotizzare forme ed orientazioni.
OMBREGGIATURA
L’ombreggiatura è determinata dalla geometria della scena e dalla riflettanza delle superfici. L’idea è quella di recuperare la geometria della scena dall’ombreggiatura, attraverso la luminosità dell’immagine I(x,y). Si tratta di un compito molto difficile.
CONTORNO
Le linee di un disegno non sono semplicemente traccia della loro forma, ma hanno diversi significati: discontinuità di profondità, di orientazione, di riflettanza, di illuminazione (ombre).
Il compito di determinarne l’esatto significato è detto etichettatura di linee.
Innanzitutto si lavora in un mondo semplificato in cui gli oggetti non hanno segni sulle superfici e sono stati rimosse le linee di discontinuità di illuminazione.
Ogni linea viene quindi classificata o come proiezione di un profilo (linea di vista tangente alla superficie) o come bordo (discontinuità normale alla superficie).
Si possono dare quindi ad ogni linea 6 possibili etichette di linea:
+ e - rappresentano i bordi convessi e concavi
à e ß sono bordi convessi occlusi
à à e ß ß rappresentano un profilo.
Se un disegno ha n lineemci sono 6n possibili assegnazioni.
C’+ poi il problema delle giunzioni. I piani delle superfici si incontrano in un vertice in quattro modi diversi, evidenziando quattro tipi di giunzione.
Esiste quindi il problema di determinare quali interpretazioni di giunte siano globalmente valide, avendo come vincolo che ogni linea della figura debba essere etichettata con la stessa sigla per tutta la sua lunghezza.
Di fatto si useranno algoritmi di soddisfacimento di vincoli, in cui le variabili sono le giunzioni, i valori le etichette e il vincolo è che ogni linea abbia una singola etichetta.
Il problema è NP-completo, ma nella pratica si giunge a soluzioni ragionevoli.
VISIONE PER MANIPOLAZIONE E NAVIGAZIONE
Uno degli scopi principali della visione è fornire informazione per la manipolazione di oggetti e la navigazione in scenari con presenza di ostacoli.
Evolutivamente la visione deve essere fatta risalire ad un’area fotosensibile posta all’estremità dell’organismo per orientarsi verso la luce o sfuggirle.
Facciamo l’esempio della guida di un autoveicolo.
Gli obiettivi sono:
Dunque l’agente deve generare sterzate appropriate, frenate, accelerazioni. Una telecamera sulla macchina inquadra la strada.
Per il controllo laterale deve mantenere la rappresentazione della posizione e dell’orientamento della macchina, ed apportare eventuali curvature dolci in base a posizione laterale della macchina, direzione rispetto alla corsia, curvatura della corsia stessa.
Per il controllo longitudinale si deve sapere la distanza del veicolo che precede, utilizzando flusso ottico o stereoscopia binoculare.
Si vede che non è necessario acquisire tutta l’informazione contenuta nell’immagine: non interessa la forma dei veicoli, la linea dell’erba accanto alla corsia, ecc. Questo permette di implementare algoritmi robusti ed efficienti.
RICONOSCIMENTO DI OGGETTI
Data una scena consistente di una serie di oggetti presi da una collezione nota O1,…,On, e un’immagine della scena presa da un punto di vista di cui non si conoscono né posizione né orientamento, vogliamo determinare:
Ad esempio, in un processo di assemblaggio, il robot deve identificare i diversi componenti e calcolare posizioni e orientazioni per il pick and place.
Il problema della rappresentazione si risolve in genere attraverso due approcci:
I cilindri generalizzati possono rappresentare efficacemente una larga classe di oggetti, perché molte forme possono essere costruite a partire da porzioni di cilindri. Il problema degli oggetti curvi resta comunque in generale irrisolto.
Vogliamo identificare un oggetto tridimensionale a partire da una sua proiezione bidimensionale, senza conoscerne la posa (posizione ed orientamento rispetto alla telecamera).
L’oggetto viene visto come un insieme di m caratteristiche o punti distinti m1,…mm come vertici di un oggetto poliedrico.
I punti vengono ruotati con rotazione R e poi traslati di t, dando luogo ad una proiezione p1,…pn , con n¹m perché alcuni punti potrebbero essere occlusi alla vista. Si ha in generale
pi = P(Rmi + t) , con P proiezione prospettica.
In generale si ritiene possibile scrivere le equazioni che legano le coordinate pi con le mi: si dimostra che , dati tre punti non allineati m1, m2, m3 nel modello e le rispettive proiezioni sul piano d’immagine p1,p2,p3, allora esistono esattamente due trasformazioni del sistema di coordinate del modello tridimensionale al sistema di coordinate bidimensionale dell’immagine.
Uno svantaggio di questo metodo è che fa uso di una libreria di modelli, il che porta ad una complessità di riconoscimento proporzionale al numero di modelli nella libreria.
Un’alternativa è l’uso di invarianti geometrici, ossia descrittori di forme che sono invarianti rispetto al punto di vista.
L’esempio più semplice di invariante proiettivo è il rapporto relativo di quattro punti su una linea, in cui la proporzione delle distanze viene preservata.
Quindi un valore misurato in un’immagine può indicizzare direttamente un modello della libreria.
Quando un invariante misurato nell’immagine corrisponde ad un valore nella libreria, viene generata un’ipotesi di riconoscimento. Ipotesi di riconoscimento corrispondenti ad uno stesso oggetto vengono unite e verificate proiettando al contrario il profilo.
Altro vantaggio è che i modelli possono essere acquisiti direttamente dalle immagini, senza passare dagli oggetti reali: questo consente l’acquisizione automatica dei modelli, ed ad es. riesce utile per il riconoscimento di immagini satellitari.
Nella figura (a) si vedono molte linee e coniche . Gli invarianti sono composti da combinazioni di linee e coniche, i cui valori indicizzano una libreria di modelli. A destra due oggetti vengono riconosciuti: la serratura con un singolo invariante con corrispondenza dei bordi pari a 50.9%, la chiave grazie a tre invarianti con corrispondenza pari a 70.7%.
Il riconoscimento del parlato comporta il passaggio dalla codifica digitale di un segnale acustico a stringhe di parole. La comprensione del parlato è il compito di passare dal segnale acustico all’interpretazione del suo significato, secondo questi tre passi:
1.
Si è visto che tutti i linguaggi umani si basano su 40-50 fonemi, corrispondenti a vocali o consonanti. Alcune combinazioni di lettere formano fonemi singoli (th, ng in inglese), oppure alcune lettere formano fonemi differenti a seconda delle parole (es. a in rat e in rate).
Ogni fonema dovrà essere fatto corrispondere ad un segnale acustico, caratterizzato da una certa frequenza o ampiezza.
2.
Per questo compito basterà ricercare le parole in un dizionario indicizzato secondo la pronuncia . Data allora la sequenza di fonemi k,ae,t si trova la parola “cat”.
Qui le difficoltà sono costituite dagli omofoni, parole differenti con gli stessi suoni (es. two e too) e dalla segmentazione, ossia del problema di decidere dove cominciano e finiscono le parole: problema grave perché anche lo spettro dei segnali mostra che le parole sono legate.
3.
Per rispondere a questa domanda è necessario fare uso di algoritmi appositi, che sono un settore specifico dell’AI.
E’ necessario per questi algoritmi molta conoscenza specifica sulle parole e sulle regole grammaticali. La conoscenza linguistica va poi connessa a quella sul mondo esterno.
In genere vengono usate la teoria dei linguaggi formali e le grammatiche context-free.
E’ utile però anche aumentare la grammatica per gestire la concordanza fra soggetto e verbo, i pronomi e la semantica.
Va poi svolta un’analisi sintattica attraverso algoritmi di parsing, oppure si possono alimentare degli specifici dimostratori di teoremi direttamente con le clausole grammaticali.
Per i casi dubbi vengono sviluppati sistemi di disambiguazione.
Alcuni sistemi di comprensione del parlato estraggono la più verosimile sequenza di parole e la passano direttamente agli analizzatori, altri si basano su più interpretazioni possibili.
ELABORAZIONE DEI SEGNALI
Quando una persona parla, emette un’onda sonora. Questa investe un microfono, che la converte in energia elettrica, con cui si può alimentare un convertitore analogico-digitale per ottenere una sequenza di bit.
Per il parlato sono opportune frequenze di campionamento di ( Hz-16KHz, i telefoni funzionano a 3 KHz. Il fattore di quantizzazione determina la precisione con cui si registra la potenza del segnale: in genere si usano da 8 a 12 bit.
8 bit a 8Hz significa mezzo Mega al minuto, troppa informazione da analizzare. E’ necessario trattare il segnale prima dell’elaborazione.
Il segnale viene raggruppato in frames di circa 10 ms, gruppi di campioni in ciascuno dei quali si ricercano fenomeni come aumento o diminuzione di frequenza o di ampiezza.
Ogni blocco ha un vettore caratteristico, che rappresenta varie componenti all’interno del blocco: ad es. la quantità di energia nei gruppi di frequenze presenti.
Altre caratteristiche importanti che vengono estratte sono l’energia totale del blocco e la differenza rispetto al blocco precedente.
In figura si vedono blocchi con un vettore di tre caratteristiche.
I blocchi si sovrappongono, in modo da non perdere le informazioni che in un’unica frammentazione verrebbero spezzate.
Infine si procede alla quantizzazione vettoriale: se vi sono n caratteristiche in un blocco, la quantizzazione vettoriale etichetta questo spazio n-dimensionale in m classi, m<<n . Alla fine si ottiene un solo byte per blocco, ottenendo una riduzione di 100 volte .
Lo stesso fonema può essere pronunciato in molti modi diversi:forte/piano, lento/veloce, acuto/basso, con rumore/senza rumore, con accenti e toni diversi da milioni di parlanti.
I sistemi di elaborazione dei segnali cercano di catturare molte caratteristiche sufficienti a riconoscere i tratti identificativi del singolo parlante.
E’ un classico compito di ragionamento con incertezza.
L’incertezza è insita nei limiti dei microfoni e della componentistica, o nell’identificazione dei fonemi o delle parole.
E’ utile il teorema di Bayes:
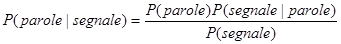
ossia dato un segnale vogliamo trovare la sequenza di parole che massimizza P(parole|segnale).
P(segnale ) è una costante, mentre P(parole) è nota come modello linguistico, ed è ciò che nel dubbio ci fa sentire “bad boy” piuttosto che “pad boy”, che è molto meno probabile.
P(segnale|parole) è invece il modello acustico: quello per cui sappiamo che cat si pronuncia molto probabilmente “k ae t” .
MODELLO LINGUISTICO
Il modello linguistico ci chiede di assegnare una probabilità ad ognuna delle possibili sequenze di stringhe.
Utilizziamo la strategia standard di definire le probabilità di un evento complesso come prodotto delle probabilità degli eventi componenti.
Sia w1,…,wn la stringa di n parole e wi la i-esima parola della stringa. Sarà allora
P(w1,…,wn) = P(w1)P(w2|w1) P(w3|w1w2)… P(wn)P(wn|w1….wn-1)
= P P(wi|w1….wn-1).
Molti questi termini sono difficili da stimare, ma possiamo approssimare P(wn|w1….wn-1) con P(wn| wn-1), ossia la probabilità di una parola è determinata solo da quella immediatamente precedente (modello a bigrammi).
Il modello si addestra contando il numero di occorrenze delle parole singole e a coppie in una serie di testi.
Ad esempio se “a” compare 10000 volte e 37 volte è seguita da “gun”, P(guni|ai-1) = 37/10000.
Automaticamente “ I have” a “a gun” avranno probabilità molto più alte di “I has” e “an gun”, cioè si cattura anche un po’ di sintassi.
Molte parole risulterebbero non presenti nei testi di addestramento, portando la probabilità a zero. Si lascia allora una parte delle probabilità alle parole che non compaiono nel testo.
I modelli a trigrammi consentono un contesto più ampio ma sono meno trattabili. Qundi spesso si ricorre a modelli misti di bigrammi, trigrammi e monogrammi (frequenza pura delle parole).
Tutti questi modelli hanno solo validità locale, ossia nei casi come “the man over there have” non possono attribuire la bassa probabilità che la frase merita.
Il modello acustico determina quali suoni vengono pronunciati in corrispondenza di certe parole.
Il modello può essere diviso in due parti:
- Dialetti differenti hanno pronunce differenti. Allora le pronunce alternative sono descritte da un modello di Markov, che descrive tutti i possibili percorsi nello spazio degli stati attribuendo una probabilità a ciascuno.
La probabilità di transizione dallo stato corrente ad un altro dipende solo dallo stato corrente e da nessun altro.
Ogni stato è un fonema, e ogni transizione ha una probabilità associata.
In questo modo si può giungere ad avere P(fonemi |parole).
Per calcolare P(segnale|fonema) si può usare un modello di Markov nascosto (Hidden Markov Model), che è un modello di Markov in cui la stessa uscita può essere presente in più stati, e ogni stato ha una distribuzione di probabilità delle possibili uscite (ciò che è nascosto è il vero stato). La probabilità sarà valutata sui vari Ci forniti dalla quantizzazione vettoriale del blocco di segnale e dal prodotto di queste probabilità.
Questo modello è potente, ma non è semplice fornire le probabilità per tutti i parametri.
In figura sono mostrati il modello di Markov con stringhe di fonemi e lo HMM per fonemi.
Abbiamo quindi:
P(parole) dal modello linguistico)
P(fonemi|parole) dal modello acustico di Markov
P(segnale|fonema) dallo HMM.
Per avere P(parole|segnale) dobbiamo combinare questi modelli.
Si potrebbe combinare tutto in un grande HMM. Se rimpiazziamo gli stati-parola con il modello di parola, otteniamo un modello con stati-fonema. Se rimpiazziamo ogni stato-fonema con il modello fonetico, otteniamo un modello con stati-valori di quantizzazione.
Dato alla fine il modello P(parole|segnale), basterebbe ora enumerare le possibili stringhe di parole e associare ad ognuna una probabilità.
Ma ci sono troppe possibili stringhe.
Si usa allora l’algoritmo di Viterbi.
Questo prende un modello HMM ed una sequenza C1, C2,…Cn, restituendo il percorso più probabile ed il valore di questa probabilità.
E’ un algoritmo iterativo che prima trova tutti i percorsi che emettono C1 come primo simbolo, poi fra questi trova il più probabile che fornisce in uscita il resto della sequenza.
A questo punto continuando si avrebbe, per M stati ed n lunghezza della sequenza, una complessità O(Mn). Invece Viterbi sfrutta la proprietà di Markov per cui il percorso più probabile da un certo stato alla fine dipende solo dallo stato stesso e non da quelli precedenti: non considereremo quindi tutti i percorsi, ma solo il percorso più probabile che porta alla fine.
In questo modo si dimostra che l’algoritmo di Viterbi passa da O(Mn) a O(bMn), dove b è il fattore di ramificazione.
Il miglior sistema di riconoscimento del parlato riconosce correttamente più del 98% di parole quando vi sono un buon microfono, piccole pause fra parole, un buon modello linguistico (con un piccolo vocabolario) e la possibilità di essere addestrato su un solo parlante.
Le prestazioni peggiorano in presenza di rumore, di vocabolario vasto, di parole pronunciate senza pause e con un parlante nuovo.
Fonte: https://homes.di.unimi.it/pizzi/AIlezioni/AGENTI%20INTELLIGENTI.doc e https://homes.di.unimi.it/pizzi/AIlezioni/PERCEZIONE.doc
Sito web da visitare: https://homes.di.unimi.it/pizzi/
Autore del testo: non indicato nel documento di origine
Il testo è di proprietà dei rispettivi autori che ringraziamo per l'opportunità che ci danno di far conoscere gratuitamente i loro testi per finalità illustrative e didattiche. Se siete gli autori del testo e siete interessati a richiedere la rimozione del testo o l'inserimento di altre informazioni inviateci un e-mail dopo le opportune verifiche soddisferemo la vostra richiesta nel più breve tempo possibile.
I riassunti , gli appunti i testi contenuti nel nostro sito sono messi a disposizione gratuitamente con finalità illustrative didattiche, scientifiche, a carattere sociale, civile e culturale a tutti i possibili interessati secondo il concetto del fair use e con l' obiettivo del rispetto della direttiva europea 2001/29/CE e dell' art. 70 della legge 633/1941 sul diritto d'autore
Le informazioni di medicina e salute contenute nel sito sono di natura generale ed a scopo puramente divulgativo e per questo motivo non possono sostituire in alcun caso il consiglio di un medico (ovvero un soggetto abilitato legalmente alla professione).
"Ciò che sappiamo è una goccia, ciò che ignoriamo un oceano!" Isaac Newton. Essendo impossibile tenere a mente l'enorme quantità di informazioni, l'importante è sapere dove ritrovare l'informazione quando questa serve. U. Eco
www.riassuntini.com dove ritrovare l'informazione quando questa serve